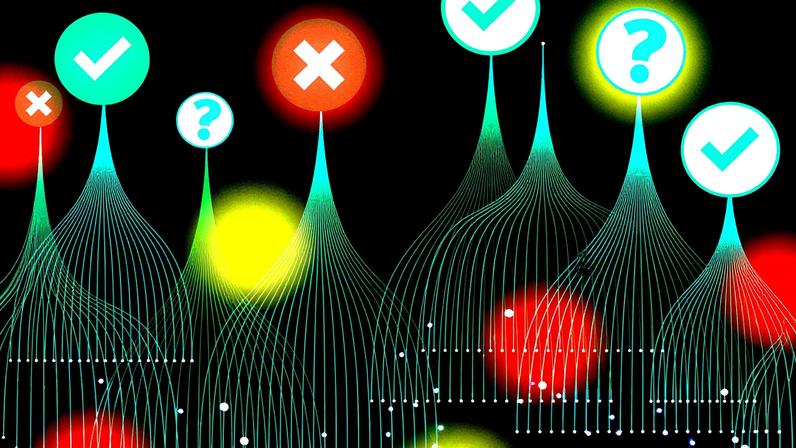
- MIT apresentou um método de incerteza total (TU) que combina incerteza epistêmica medida pela discordância entre modelos com arquitetura semelhante e incerteza aleatória de respostas, avaliando confiabilidade de previsões de grandes modelos de linguagem.
- A abordagem compara a resposta de um modelo-alvo com um pequeno conjunto de modelos de diferentes empresas, usando similaridade semântica para estimar a incerteza epistêmica de forma mais precisa.
- O TU alia essa estimativa a uma medida de auto-coerência (self-consistency) para refletir melhor a confiança nas respostas, reduzindo a probabilidade de falsos positivos em previsões confiantes porém incorretas.
- Os testes, em dez tarefas realistas como perguntas e respostas, resumo, tradução e raciocínio matemático, mostraram que o TU supera as métricas anteriores e identifica previsões não confiáveis com maior eficácia.
- O estudo sugere que o TU pode reduzir o número de consultas necessárias, diminuindo custos computacionais, e aponta direções para melhorar o desempenho em tarefas abertas no futuro.
A MIT apresentou uma nova metodologia para quantificar incerteza em grandes modelos de linguagem (LLMs), visando identificar respostas confiantes porém incorretas. O objetivo é reduzir alucinações e deixar o usuário mais informado sobre quando confiar no modelo. A técnica envolve comparar a resposta de um modelo-alvo com as de um grupo de LLMs semelhantes.
A equipe mostrou que medir o desacordo entre modelos ajuda a capturar a chamada incerteza epistêmica, diferente da simples confiança interna de um único sistema. Com esse enfoque, adicionaram uma métrica de incerteza total que combina resultados de diferentes modelos para avaliar a confiabilidade das respostas.
A pesquisa foi conduzida por Kate Hamidieh e outros especialistas do MIT, em colaboração com o MIT-IBM Watson AI Lab e a Worcester Polytechnic Institute. O estudo avaliou a abordagem em 10 tarefas realistas, como question answering e raciocínio matemático.
Nova métrica de incerteza
A técnica propõe medir a divergência entre o modelo-alvo e um ensemble pequeno de modelos de tamanho e arquitetura semelhantes. A semântica das respostas é analisada para estimar melhor a incerteza epistêmica, conforme os pesquisadores. Modelos de diferentes empresas compõem o conjunto para ampliar a diversidade de respostas.
Os autores ressaltam que a soma entre a incerteza epistêmica e a incerteza aleatória resulta na incerteza total (TU), que melhor reflete a confiabilidade de uma previsão. Em testes, TU superou métodos convencionais em detectar previsões não confiáveis.
Resultados e impactos
A TU identificou com maior consistência saídas potencialmente incorretas, associadas à alucinação de LLMs, especialmente em tarefas com respostas únicas. A abordagem pode também fortalecer respostas corretas durante o treinamento, elevando o desempenho geral. Os experimentos mostraram redução de consultas necessárias para estimar a incerteza.
Autoras destacam que a incerteza epistêmica tem maior impacto em tarefas com resposta singular, como perguntas factuais, e pode ter desempenho menor em tarefas mais abertas. Futuras pesquisas visam aprimorar a técnica para perguntas abertas e explorar outras formas de incerteza aleatória.
Sobre o financiamento e autoria
O trabalho contou com financiamento parcial do MIT-IBM Watson AI Lab. Além de Hamidieh, integram o estudo Veronika Thost, Walter Gerych, Mikhail Yurochkin e a pesquisadora sênior Marzyeh Ghassemi. A equipe descreve a metodologia em publicação acadêmica associada.



Entre na conversa da comunidade